Today I begin the study of Reinforcement Learning, which is one of the interesting research field i would like to study. These few years we see the research team DeepMind has done a lot in this field, and made numbers of achievements. We see AlphaGo in GO, we see AlphaZero in multiple chess games, we also see DeepMind tried to create a human-like ai in the game Starcraft II. Although finally they didn’t successfully create an ai that behaves like human, maybe due to the limitation of current algorithms, ai architecture or other reasons. However, they also discover many interesting ai behaviors, like ai will lift the base on the sky, in order to avoid enemies’ attack. They are also some already made human-like ai in games like Super Mario using Reinforcement Learning.
For me, I am expecting one day i can create an immersive and powerful ai in some RPG games, like The Elder of Scrolls : Skyrim or Sim series. I am also expecting one day the NPC in games can be like a human or more crazy, we cannot even distinguish between the guy facing you is a real person or a NPC. That’s really cool!
Also, I am always thinking that, a good ai can be composed of some basic general principles, instead of combination of a vast number of special purpose tricks, procedures and heuristics. In these days, most of the ai is realized by finite state machine and behavior trees. I am not saying they are not good technologies, in truth they are very powerful in designing a good ai. But that’s not enough for an ai to behave like a human. We can try making a more complex ai, but that’s just adding more characteristics to an ai. We need some way to let ai have the ability to learn something, in the guidance of some general principles. That’s why i am interested in this field.
In the remaining of this article, I will write down what I learn and what I think after reading the book < Reinforcement Learning : An Introduction > by Richard S. Sutton and Andrew G. Barto.
Definition
Reinforcement learning is learning what to do — how to map situations to actions — so as to maximize a numerical reward signal.
Trial-and-error and delayed reward are the two most important distinguishing features of reinforcement learning.
Trial-And-Error
The learner is not told which actions to take, but instead must discover which actions yield the most reward by trying them.
Delayed Reward
In the most interesting and challenging cases, actions may affect not only the immediate reward but also the next situation and, through that, all subsequent rewards.
Exploration and Exploitation
The agent has to exploit what it has already experienced in order to obtain reward, but it also has to explore in order to make better action selections in the future.
In all, the agent must try a variety of actions and progressively favor those that appear to be best.
Elements
Reinforcement learning has the following four main elements.
Policy
A policy defines the learning agent’s way of behaving at a given time.
A policy is like a mapping from state(environment) to action(decision) — In each specific case of state, which action we decide to choose. That’s also what reinforcement learning learns, to select the best policy in the policy space.
Reward Signal
A reward signal defines the goal in a reinforcement learning problem.
Reward helps us to decide whether a policy is good or not, or let’s say to estimate an action in current state.
Value Function
A value function specifies what is good in the long run.
Different from reward, a value of a state will take account of all rewards over the future, starting from the current state, to dicide whether a policy is good or not in the future. In fact, the most important component of almost all reinforcement learning algorithms we consider is a method for efficiently estimating values.
Model of Environment
A model of environment allows inferences to be made about how the environment will behave.
Here we don’t just look at the current state and reward, but also take account of the environment, predict the environment response to the policy we adopt. By this mean, we can obtain the next state and also the next reward, while in this case we don’t need trial-and-error.
Difference with Evolutionary Method
Evolutionary methods such as genetic algorithm, genetic programming, simulated annealing and other optimization methods have been used to approach reinforcement learning without using value function. Each time they select a policy from the policy state, use it to interact with environment multiple times, and finally obtain one with the best reward.
However, evolutionary method ignores much of the useful information during the process, and only care about the final result(winning posibility). This may sometimes cause misleading.
An Example: Tic-Tac-Toe
Traditionary solution:
- Minimax
- Dynamic Programming
- Evolutionary Method
In reinforcement learning, we use the rule of “temporal difference learning method”.
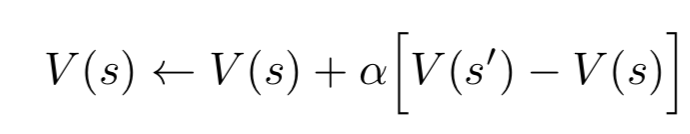
While we are playing, we change the values of the states in which we find ourselves during the game. We attempt to make them more accurate estimates of the probabilities of winning. To do this, we need to update the previous state every time we select an optimal action and go into a new state.
If the step-size param- eter is reduced properly over time, then this method converges, for any fixed opponent, to the true probabilities of winning from each state given optimal play by our player.
Some Tips
- We can teach the agent some prior knowledge to improve search efficiency.
- Behaviors(Actions) can be continuous instead of descrete, also reward function can be.
- State set can be large or even infinity. How well a reinforcement learning system can work in problems with such large state sets is intimately tied to how appropriately it can generalize from past experience. Here supervised learning, neural network and deep learning may help.
- A model of environment(model-based system) may help to improve the learning effect. It depends on the difficulty to obtain (or learn) a good environment model which is reasonably accurate to be useful.